Kafka
카프카는 분산 스트리밍 플랫폼(streaming platform)이다.
- mom으로 구현한 MQ System
- message broker
- pub/sub 모델
- 높은 throughput(처리량)
- 빠른 처리 속도
- 파일에 데이터를 기록한다.
용어
브로커(Broker) - 카프카 클러스터의 서버 또는 노드를 말합니다.
토픽(Topic) - 프로튜서와 컨슈머들이 카프카로 보낸 자신들의 메시지를 구분하기 위한 카테고리
파티션(Partition) - 토픽을 분할 한 단위. 파티션을 늘려 병렬처리를 통해 처리속도를 높일 수 있음
프로듀서(Producer) - 메시지를 생산하여 토픽에 저장하는 개체
컨슈머(Comsumer) - 토픽 이름으로 저장된 메시지를 가져가는 개체
Goal
- producer와 consumer 사이의 느슨한 연결
- binary 데이터 형식을 사용한 다양한 데이터 format 관리
- 기존의 클러스터에 영향을 주지 않고 서버 확장(scale out) 지원
Concept
- 카프카는 하나 이상의 서버로 구성되는 클러스터에서 작동한다.
- 카프카 클러스터는 topic이라고 불리는 카테고리에 데이터 레코드 스트림을 저장한다.
- 각 레코드는 key, value, timestamp로 구성된다.

Broker, Zookeper
- broker : 카프카 서버. broker.id=1..n으로 함으로써 동일한 노드내에서 여러개의 broker서버를 띄울 수도 있다.
- zookeeper: broker 노드의 상태 정보를 관리 한다.. zookeeker는 컨트롤러를 선정하는데 컨트롤러는 파티션 관리를 책임지는 브로커 중 하나이다. 파티션 관리는 리더 선정, 토픽 생성, 파티션 생성, 복제복 관리를 포함한다. 또한 리더 노드가 다운되면 컨트롤러는 팔로워 중 파티션 리더를 선정한다. 선정 방식에서 과반 수 투표방식으로 결정하기 때문에 홀수로 구성해야 하고, 과반수 이상 살아 있으면 정상 동작한다.
API
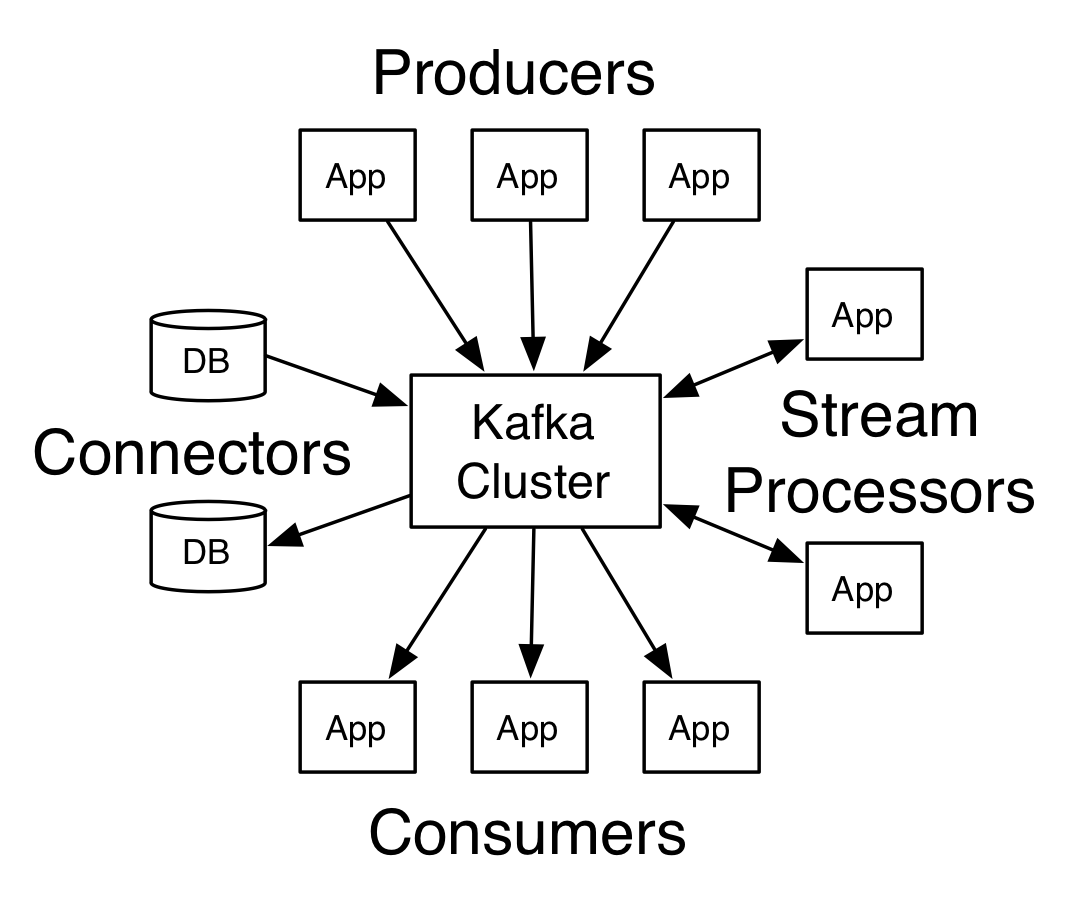
카프카의 주요 API들은 아래와 같다.
- Producer API : 애플리케이션은 이 API를 이용해서 하나 이상의 카프카 토픽에 스트림 레코드를 게시할 수 있다.
- Consumer API : 애플리케이션은 이 API를 이용해서 하나 이상의 카프카 토픽으로 부터 스트림 레코드를 구독 할 수 있다.
- Streams API : 애플리케이션이 하나 이상의 토픽에서 입력 스트림을 읽고 변환해서 하나 이상의 출력 토픽으로 스트림을 보낼 수 있도록 한다.
- Connector API : Connector를 이용해서 재 사용 가능한 Producer 혹은 Consumers를 카프카 토픽에 연결 할 수 있다. 예를 들어 관계형 데이터베이스 컨넥터는 테이블에 대한 변경 사항을 캡처할 수 있다.
Topic
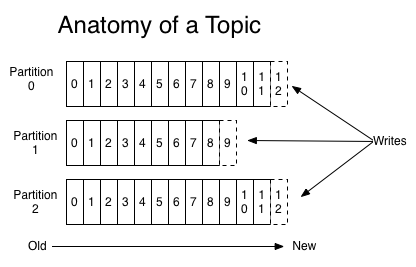
- 카프카의 모든 메시지는 byte array로 표현된다.
- 모든 토픽은 하나 이상의 파티션으로 나뉘어져 있다.
- 파티션 내 한 칸은 로그라고 불린다.
- 카프카 클러스터는 파티션에 설정된 모든 레코드에 보관 기간에 따라 저장한다. 기본 값은 7일이다.
- 여러 개로 나뉘어진 파티션은 내부 record에 timestamp를 갖고 있기 때문에 도착한 순서에 맞게 저장한다.

- producer는 토픽에 메시지를 저장한다.
- consumer는 다른 MQ와는 다르게 topic으로 부터 메시지를 pull 방식으로 가져온다.
- producer는 로그 선행 기입 파일 마지막에 메시지를 write한다.
- consumer는 주어진 토픽 파티션에 속한 로그 파일에서 메시지를 가져 온다. consumer 자체가 능등적으로 offset을 저장하고 있으며 offset으로 데이터를 가져 오기 때문에 가볍다.
파티션의 분산 및 복제
- 물리적으로 토픽은 하나 이상의 파티션을 다른 broker에게 분배될 수 있다.
- 만일 순서가 중요한 데이터라면, 파티션을 1개로 구성하는 것도 고려할 수 있다.
- 파티션을 복제하면 roundRobin 방식으로 쓰여 진다.
- 파티션을 여러개로 구성하면 여러 쓰레드에서 병렬로 처리되기 때문에 높은 처리량을 보장 받을 수 있지만 순서 보장 고려, producer 메모리 증가, 장애 복구 시간 증가 등 여러가지를 고려해야 한다.
- 파티션은 지정된 복제 팩터에 따라 카프카 클러스터 전역에 복제되는데 각 파티션은 leader 브로커와 follower 브로커를 가지며, 파티션에 대한 모든 읽기와 쓰기 요청은 리더를 통해서만 진행된다.
Comsumer Group

- 카프카는 큐(queue)와 발행/구독(Pub/Sub) 두 가지 모델을 지원한다. 큐 모델 에서 특정 메시지는 하나의 인스턴스(C1,C2..)에서만 꺼내갈 수 있지만, 발행/구독 모델에서는 특정 메시지를 하나 이상의 인스턴스에서 꺼내갈 수 있다.
- pub/sub 모델을 통해, 복수의 Consumer로 이루어진 Consumer group을 구성하여 1 topic의 데이터를 분산하여 처리가 가능하다.
이 때 토픽의 파티션 수가 컨슈머 그룹 내 수보다 클 때 모두 처리가 가능한데, 만일 컨슈머 그룹이 더 크다면 1개 이상의 컨슈머는 idle(유휴) 상태가 된다.
참고:
https://coding-start.tistory.com/192?category=790331 [코딩스타트]
https://www.joinc.co.kr/w/man/12/Kafka/about
https://kafka.apache.org/introhttps://www.joinc.co.kr/w/man/12/Kafka/about
Apache Kafka
Apache Kafka: A Distributed Streaming Platform.
kafka.apache.org
'Cloud & NoSQL & Middleware > Kafka' 카테고리의 다른 글
| Kafka - Consumer API (0) | 2019.11.03 |
|---|---|
| Kafka - Producer API (0) | 2019.11.03 |
| Zookeeper api 테스트 (0) | 2019.11.02 |
| Zookeeper (0) | 2019.11.02 |